Rapport d'incident #001 (07/08/2022)
Le mystère du redémarrage après 15min d'inactivité (par Nicolas)
L'incident
Tout commence le 7 Aout 2022 à 17h, lorsque je me rends compte via le système de monitoring CLUB1, mis en place grâce à UptimeRobot, que le serveur n'a pas été accessible pendant une quinzaine de minutes, de 15h20 à 15h35.
La première hypothèse fut que le routeur fourni par Bouygues Télécoms avait dû faire une mise-à-jour, ce qui aurait pu occasionner une telle coupure. Mais après vérification sur le dashboard, pas de doute, c'est bien le serveur lui-même qui a eu un problème sur cette tranche horaire, c'est là que le mystère commence.
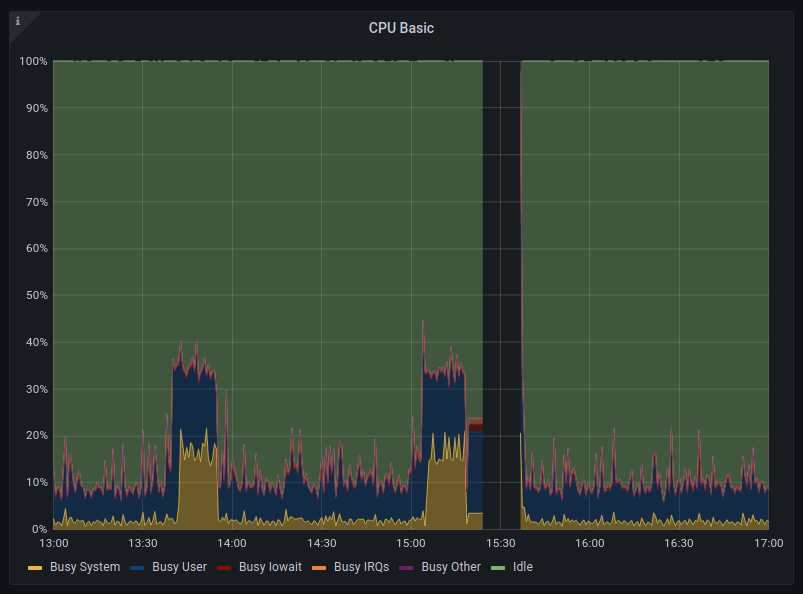
Après vérification de tous les logs (journaux) du serveur, en particulier kern.log.* et syslog.* le mystère ne fait que s'épaissir. Aucune ligne ne semble indiquer d'erreur et le log s'arrête brusquement avec une ligne remplie de "caractères nuls", pour reprende une quinzaine de minutes plus tard avec un log de démarrage de Linux.
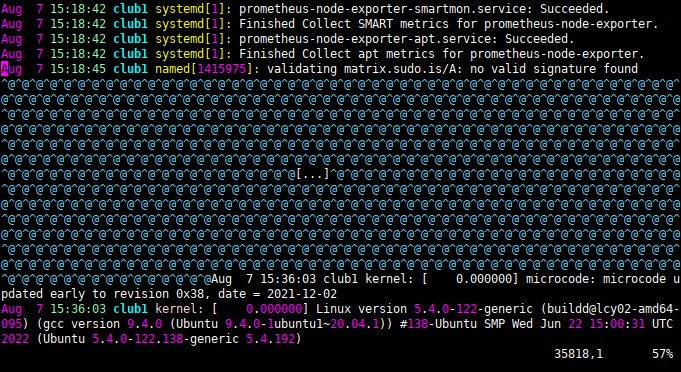
Ce log suggère que le serveur aurait subit un arrêt brutal, potentiellement causé par une coupure de courant. Le fait qu'il ait redémarré plus tard aurait pu être expliqué par la politique Start on Power selectionnée dans le BIOS. Cependant le serveur est censé communiquer avec l'UPS via NUT pour s'arrêter proprement avant que la batterie soit épuisée et des messages d'avertissement auraient dû être émis tout au long de la coupure de courant. Or rien de tout ça n'est arrivé. Personne n'était présent pour débrancher physiquement le serveur, donc une panne de l'UPS est suspectée, mais le fait que le serveur ait par la suite redémarré écarte également cette hypothèse.
J'ai finalement eu l'idée de vérifier les potentiels logs disponibles au niveau de l'IPMI, et ces deux messages étaient présents :
439 2022/08/07 12:33:59 #0xca Watchdog 2 Timer Interrupt - Assertion
440 2022/08/07 12:34:00 #0xca Watchdog 2 Hard Reset - Assertion
Une rapide recherche m'amène sur un post du forum TrueNas qui me permet de comprendre qu'il s'agit d'une fonctionnalité de la carte-mère :
The watchdog is intended to automatically reset the system if it detects that the OS has frozen/crashed. If you have a Supermicro board, please check if you have a jumper on the motherboard for the watchdog, this might affect it.
Le chien de garde (watchdog) est destiné à réinitialiser automatiquement le système s'il détecte que le système d'exploitation s'est figé/crashé. Si vous avez une carte Supermicro, veuillez vérifier si vous avez un cavalier sur la carte mère pour le chien de garde, cela pourrait l'affecter.
Les éléments commencent donc enfin à s'assembler de manière cohérente. Le décalage horaire des entrées du log de l'IPMI provenait d'un réglage incorrect de son horloge interne et le compte à rebours était effectivement réglé sur 15 minutes (900 secondes). C'est donc bien le Watchdog du BMC (le composant principal de l'IPMI) qui a déclenché le redémarrage du serveur.
$ sudo bmc-watchdog --get
Timer Use: SMS/OS
Timer: Running
Logging: Enabled
Timeout Action: Hard Reset
Pre-Timeout Interrupt: None
Pre-Timeout Interval: 0 seconds
Timer Use BIOS FRB2 Flag: Clear
Timer Use BIOS POST Flag: Clear
Timer Use BIOS OS Load Flag: Clear
Timer Use BIOS SMS/OS Flag: Clear
Timer Use BIOS OEM Flag: Clear
Initial Countdown: 900 seconds
Current Countdown: 877 seconds
Le scénario serait donc le suivant : le serveur aurait complètement arrêté de répondre, probablement à cause d'un blocage complet du noyau, il aurait ainsi arrêté d'envoyer son heartbeat au BMC, qui aurait décidé de le redémarrer au bout de 15 minutes.
Une fois encore, une rapide recherche m'a mis sur la piste d'autres occurences de problèmes similaires. Il semblerait donc qu'il y ait un problème avec la version 5.4.0-122.138 du noyau Linux utilisé par Ubuntu.
TL;DR : Le noyau Linux 5.4.0-122.138 s'est visiblement bloqué en cours d'exécution ce qui a mis complètement hors-service le serveur, qui s'est finalement automatiquement redémarré au bout de 15 minutes.
La réparation
Pour réparer ce problème, le plus simple était pour le moment de retourner sur une version antérieure du noyau. Heureusement, la plupart des distributions Linux conservent les versions installées précédemment, ce qui permet de les réutiliser le cas échéant. Cependant, la méthode habituelle pour selectionner la version à utiliser se fait lors du démarrage, au niveau du menu de GRUB, lequel n'est pas accessible à distance. L'IPMI aurait pu me permettre de le faire mais je n'avais pas la possibilité d'accéder au réseau local à ce moment-là. Et de toute façon, je préférais trouver une solution plus durable que de devoir sélectionner la bonne version à chaque redémarrage.
Un post du forum Ubuntu m'a permis de découvrir une technique très pratique pour sélectionner l'entrée par défaut de GRUB depuis Linux. Mais comme il y a quelques petites erreurs dans celui-ci, voilà la procédure que je recommande :
Récupération de la liste des entrées du menu de GRUB à l'aide de la commande suivante.
awk -F"'" '/(menuentry|submenu) / { print $2 }' /boot/grub/grub.cfgVoilà un exemple de retour possible. Il faut connaitre un minimum le menu de GRUB sur Ubuntu, pour savoir que
Advanced options for Ubuntuest en fait un sous-menu contenant les 4 entrées suivantes.Ubuntu Advanced options for Ubuntu Ubuntu, with Linux 5.4.0-122-generic Ubuntu, with Linux 5.4.0-122-generic (recovery mode) Ubuntu, with Linux 5.4.0-121-generic Ubuntu, with Linux 5.4.0-121-generic (recovery mode) UEFI Firmware SettingsConfiguration de la valeur par défaut dans un nouveau fichier. L'entrée qui nous intéresse dans notre cas est
Ubuntu, with Linux 5.4.0-121-generic, mais elle se trouve dans un menu, il faut donc aussi le spécifier en utilisant>pour les séparer.echo 'GRUB_DEFAULT="Advanced options for Ubuntu>Ubuntu, with Linux 5.4.0-121-generic"' \ | sudo tee /etc/default/grub.d/default-5.4.0-121.cfgMise-à-jour de GRUB avec cette nouvelle configuration :
sudo update-grubPour annuler ce changement, il suffit de supprimer le fichier ajouté et de réitérer cette dernière étape.
Conclusion
Cette panne mystérieuse nous aura finalement permis de découvrir une fonctionnalité de notre carte-mère que nous ignorions jusqu'ici, et nous sommes bien contents qu'elle soit présente. C'est une confirmation de plus que le choix du matériel est important et que celui qui a été choisi est adapté à notre cas d'usage. Sans cette fonctionnalité de Watchdog BMC nous n'aurions eu aucun moyen de reprendre la main sur le serveur à distance, ce qui aurait entrainé une interruption de service bien plus longue.
Pour le moment la version du noyau utilisée par CLUB1 sera donc gelée à 5.4.0-121. Elle sera mise-à-jour plus tard, en espérant que le bug sera résolu d'ici là.